Advancements in Language Models: A Comprehensive Overview
Greetings, fellow language enthusiasts! Today, we embark on an exciting exploration into the realm of Natural Language Processing (NLP), focusing on the transformative power of models like BERT, GPT, and more.
A Brief History of Natural Language Processing
To truly understand the impact of transformers, let’s take a step back and trace the evolution of NLP.
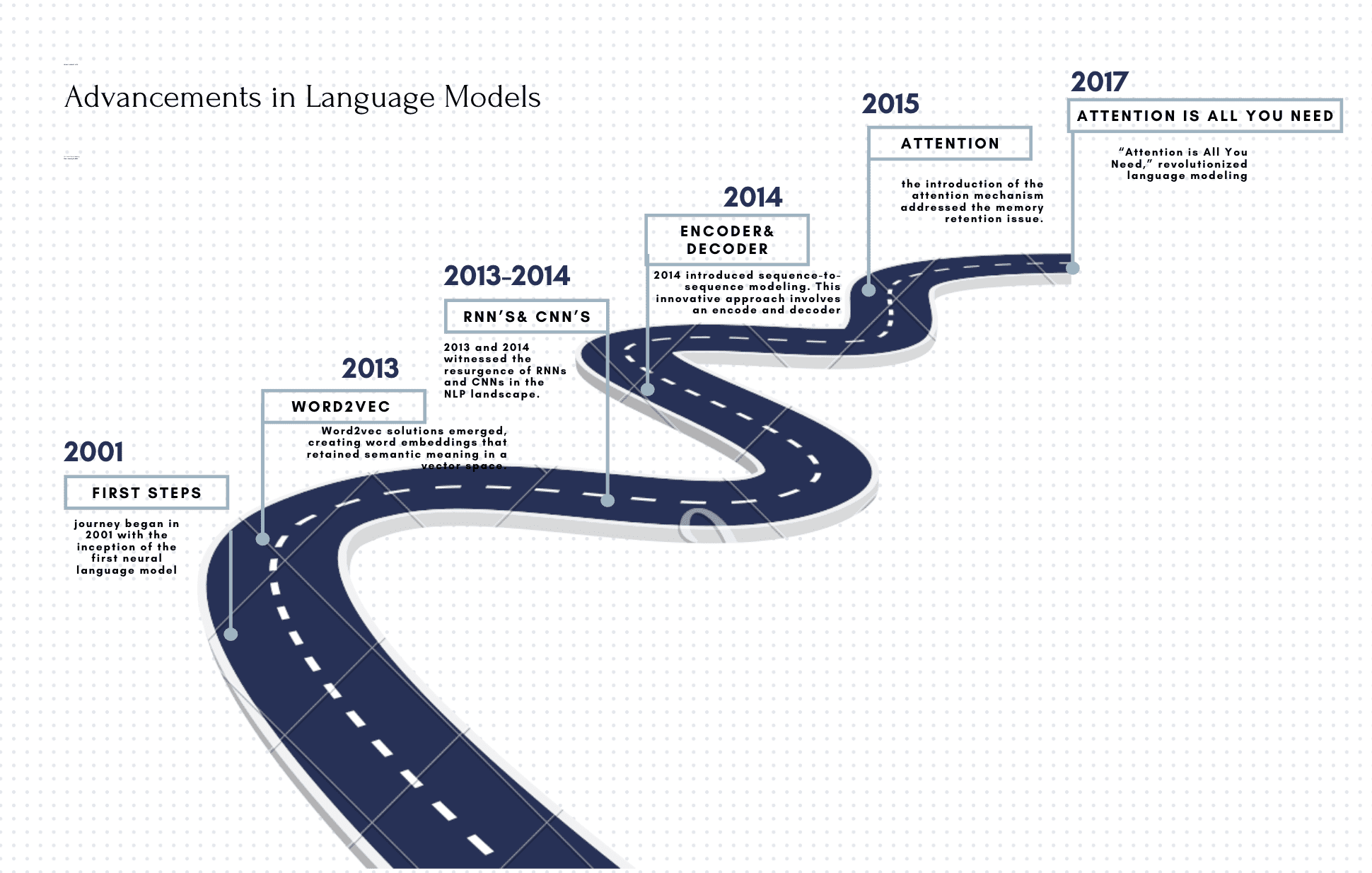
Our journey began in 2001 with the inception of the first neural language model. This marked the dawn of using deep learning networks to predict future words in a sentence, a concept that resonates throughout our discussions on language modeling.
Fast forward to 2013, a crucial year when Word2vec solutions emerged, creating word embeddings that retained semantic meaning in a vector space. However, with great innovation came a challenge – biases. Large-scale corpora used for training these models inadvertently introduced biases, a topic we’ll delve into deeply.
Unmasking Bias in Word Embeddings
In 2013, as we harnessed the power of continuous bag-of-words and skip-gram networks, it became evident that biases crept into our models.
We encounter two types of bias – direct bias, where specific words are inherently linked to particular attributes, and indirect bias, where subtler correlations lead to unexpected associations. Throughout our exploration, we will confront and address these biases, comprehending their implications on language models. Additionally, we’ll delve into other instances of bias, such as cultural biases, gender biases, regional biases, and contextual biases, expanding our understanding of the intricate nature of biases in word embeddings.
Rise of Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs)
2013 and 2014 witnessed the resurgence of RNNs and CNNs in the NLP landscape. Although these architectures had roots in the 20th century, the 21st-century advancements propelled them into the forefront of NLP tasks.
Enter Sequence to Sequence Modeling
Expanding on the newly simplified training of RNNs, 2014 introduced sequence-to-sequence modeling. This innovative approach involves an encoder, usually an RNN, The job of the encoder is to encode the information from the input sequence into a numerical representation that is often called the last hidden state. The decoder, also an RNN, would then generate a variable-length output sequence from the last hidden state. However, a drawback emerged – the challenge of retaining long-term information due to the fixed-length vector.
The Birth of Attention Mechanism
In 2015, the introduction of the attention mechanism addressed the memory retention issue. This mechanism enabled the decoder to access intermediate hidden states of the encoder, allowing it to pay attention to every token along the way. This pivotal development paved the way for the grand entrance of the transformer in 2017.
“Attention is All You Need”: The Transformer Era
The groundbreaking paper in 2017, titled “Attention is All You Need,” revolutionized language modeling. It proposed that attention, rather than RNNs, could be the primary mechanism powering language models. This idea gained widespread acclaim, leading to the rise of pre-trained language models by 2018.
The Era of Pre-trained Language Models: BERT, GPT, T5, and More
Models like BERT, GPT, and T5 took center stage, pre-trained on massive corpora to grasp general language rules. The impact was evident across various NLP tasks, showcasing substantial improvements compared to previous state-of-the-art results. Elmo, a transformer-based architecture, particularly shone as a starting point for tasks like question-answering and named entity recognition.
As we journey through the fascinating landscape of NLP, we’ll continue to explore the intricacies of transformers, shedding light on their applications, challenges, and the ever-evolving tapestry of natural language processing. Stay tuned for more insights and revelations in our quest to unlock the secrets of language through the lens of cutting-edge models.