Transformers: A Revolution in Natural Language Processing
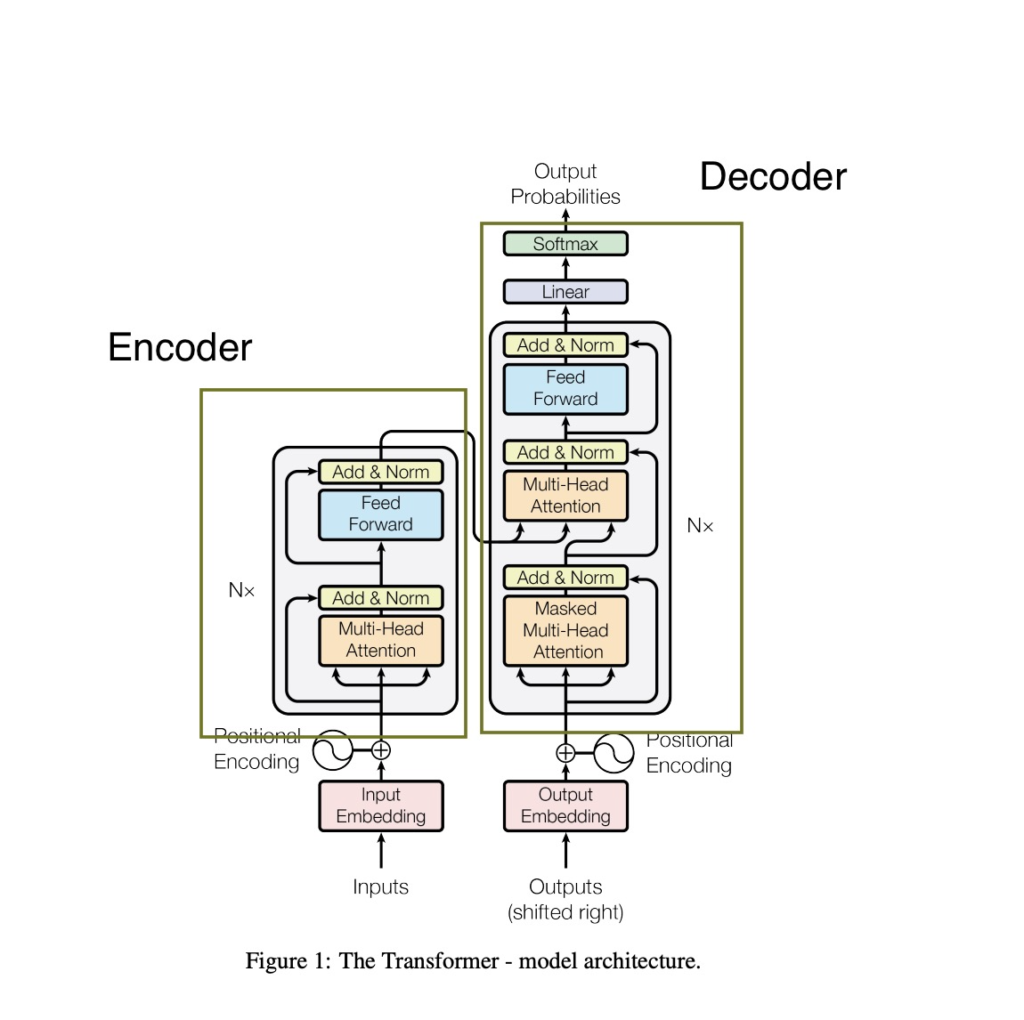
The Transformer, introduced in the pivotal 2017 paper “Attention is All You Need,” stands as a testament to the evolution of NLP. This architecture, armed with various forms of attention mechanisms—multi-headed attention, masked multi-headed attention, and cross attention—represents a paradigm shift in how we approach language processing.
Transformers outshone traditional Recurrent Neural Networks (RNNs) in machine translation tasks, paving the way for transformative models like Generative Pretrained Transformer (GPT) and Bidirectional Encoder Representations from Transformers (BERT). The shift not only elevated translation quality but also introduced a more cost-effective training process.
By combining the Transformer architecture with unsupervised learning, these models eliminated the necessity of crafting task-specific architectures from scratch, achieving remarkable success across various NLP benchmarks. The Transformer’s reliance on self-attention further set it apart, discarding the need for recursive connections found in RNNs and LSTMs.
The Essence of Language Models
At the core of transformers lies the language model, a concept crucial for comprehending how these models grasp language rules and navigate the intricacies of sentences within extensive corpora.
Language Models: Auto-regressive vs. Auto-encoding
A fundamental aspect of language modeling involves training a model to predict a missing word or token within a sequence. Two primary types of language models, auto-regressive and auto-encoding, play distinct roles in this process.
Auto-regressive Language Model:
Imagine the sentence,
“Should you neglect to _____ at the crossroads, you shall incur a penalty.”
In an auto-regressive task, the model predicts a future token based on either the past or future context. This includes forward prediction (predicting the blank based on the preceding context)
Should you neglect to _____
or backward prediction (predicting the blank based on the following context)
_____ at the crossroads, you shall incur a penalty.
Auto-regressive(mostly forward prediction) models excel in tasks like auto-complete, prevalent in natural language generation.
Auto-encoding Language Model:
In contrast, an auto-encoding language model seeks to learn representations of an entire sequence by predicting a token given both past and future context. The task presented earlier exemplifies this approach.
“If you don’t _____ at the sign, you will get a ticket,”
Auto-encoding models shine in understanding entire sequences, excelling in tasks such as sequence classification and named entity recognition.
Understanding the Core Concepts
To truly grasp the significance of transformers, we need to delve into the foundational concepts that underpin their success:
1. The Encoder-Decoder Framework
Before transformers, recurrent architectures like LSTMs dominated NLP. These architectures featured a feedback loop that allowed information to propagate through network connections, making them ideal for sequential data modeling. The encoder-decoder framework, particularly in machine translation, involves encoding input sequences into a numerical representation and decoding them to generate the output sequence.
This architectural masterpiece consists of two fundamental components:
1. Encoder
- Function: Converts an input sequence of tokens into a sequence of embedding vectors, often referred to as the hidden state or context.
- Role: Initiates the processing of the input, laying the foundation for subsequent decoding.
2. Decoder
- Function: Utilizes the encoder’s hidden state to iteratively generate an output sequence of tokens, predicting one token at a time.
- Role: Transforms the encoded information into a meaningful output sequence.
Transformer’s encoder and decoder blocks found versatility as standalone models. Three primary types of Transformer models have emerged:
1. Encoder-only
- Function: Converts input text into a rich numerical representation, ideal for tasks like text classification or named entity recognition.
- Notable Examples: BERT, RoBERTa, DistilBERT
- Key Feature: Bidirectional attention, considering both left and right contexts for token representation.
2. Decoder-only
- Function: Autocompletes sequences by predicting the most probable next word given a prompt.
- Notable Examples: GPT Models
- Key Feature: Causal or autoregressive attention, relying on the left context for token representation.
3. Encoder-decoder
- Function: Models complex mappings from one text sequence to another, suitable for tasks like machine translation and summarization.
- Notable Examples: BART, T5
- Key Feature: Combines encoder and decoder components for comprehensive sequence transformations.
2. Attention Mechanisms
Attention mechanisms addressed a bottleneck issue in the encoder-decoder architecture. Instead of relying on a single hidden state to represent the entire input sequence, attention allowed the decoder to access all encoder states with varying weights.
Attention mechanism enables the model to focus on specific parts of input sequences. Scaled dot product attention is a pivotal element in the encoder of the transformer, and it operates through the manipulation of three matrices: query, key, and value.
The Intuition Behind Query, Key, and Value Matrices
Each matrix (Q, K, and V) carries intuitive significance. The query matrix signifies the information the model is searching for in a given input sequence. The key matrix indicates the relevance of each word to the query, capturing the importance of individual words in the context of the entire sentence. Lastly, the value matrix encapsulates the contextless meaning of input tokens.
Transforming Contextless to Context Full: The Attention Formula
The scaled dot product attention formula unfolds in a series of calculated steps. Starting with the multiplication of the query and key matrices, we create an attention score matrix representing the relevance of each token to others in the sequence. This matrix undergoes scaling, softmax application, and multiplication with the value matrix to transform contextless information into a context-full representation.
The Quest for Selective Attention
Imagine a scenario where a machine is tasked with understanding a sentence. The question arises: How does it discern which tokens to pay attention to? Is it seeking pronoun antecedents or establishing direct object relations? To address this, the creators of Transformers introduced the notion of multi-headed attention.
Unveiling Multi-Headed Attention
At its core, multi-headed attention involves incorporating not one but multiple attention mechanisms within each encoder. Instead of a single pass through an input representation, each encoder boasts several smaller attention mechanisms, each with a distinct set of weights. These attention mechanisms operate concurrently, focusing on different aspects of the input.
Let’s delve into the mechanics. Consider a matrix representing our input tokens. In a traditional attention mechanism, we perform calculations on this matrix using weights for query, key, and value. Multi-headed attention takes this a step further. It repeats the process with different sets of weights, producing multiple results. Importantly, these results don’t communicate with each other; they operate independently.
Each encoder in BERT, for instance, possesses multiple attention heads. In the BERT base model, there are 12 encoder layers, each with 12 attention heads, summing up to 144 simultaneous scaled dot product attention calculations. The idea is simple: each attention head hones in on distinct grammatical rules. When combined, they contribute to a comprehensive understanding of language.
3. Transfer Learning in NLP
Transfer learning, a common practice in computer vision, became a game-changer in NLP. Unlike traditional supervised learning, transfer learning involves pretraining a model on a source domain and fine-tuning it for a specific task. ULMFiT introduced a comprehensive framework for adapting pre-trained LSTM models to various tasks, marking a crucial advancement in transfer learning for NLP.
For instance, a pre-trained BERT model, having navigated through English Wikipedia and BookCorpus, carries a nuanced understanding of language. Models are initially pre-trained on vast, unlabeled text corpora, honing their language understanding without a specific useful objective. The subsequent fine-tuning occurs on a labeled dataset, usually smaller in scale but tailored to the specific downstream NLP task.
A Peek into BERT’s Training
Consider BERT, a heavyweight in NLP. Its pre-training involves exposure to the entirety of English Wikipedia (2.5 billion words) and BookCorpus. During this phase, BERT learns intricate language nuances and relationships, setting the stage for versatile applications.
Fine-Tuning Strategies
Fine-tuning, the second act in the transfer learning narrative offers three distinct strategies:
- Update Entire Model: This approach involves updating all aspects of the transfer learning model, including pre-existing weights and any additional layers added for the downstream task. While comprehensive, it is the slowest.
- Freeze a Subset: By freezing a subset of the model, typically the initial layers, practitioners strike a balance between preserving pre-training knowledge and accelerating fine-tuning.
- Freeze Entire Model: The fastest method entails freezing the entire pre-trained model, updating only the task-specific layers. Though efficient, this strategy often sacrifices performance on the downstream task, especially in nuanced domains.
The choice of fine-tuning strategy depends on the specific task and data at hand. The balance lies in optimizing training time while ensuring the model captures domain-specific intricacies.
The journey from attention mechanisms to transfer learning and the rise of GPT and BERT showcases the relentless pursuit of excellence in the quest for machines to comprehend and generate human-like language.
we’ll continue to explore on practical implementations, witnessing the synergy between pre-trained models and fine-tuning strategies. Stay tuned as we unravel the full potential of transfer learning in the transformative landscape of transformers.